AI算力需求规模空前 Web3有何用武之地?
重点内容:
我们在讨论分布式算力在训练时的应用,一般聚焦在大语言模型的训练,主要原因是小模型的训练对算力的需求并不大,为了做分布式去搞数据隐私和一堆工程问题不划算,不如直接中心化解决。而大语言模型对算力的需求巨大,并且现在在爆发的最初阶段,2012-2018,AI的计算需求大约每4个月就翻一倍,现在更是对算力需求的集中点,可以预判未来5-8年仍然会是巨大的增量需求。
在巨大机遇的同时,也需要清晰的看到问题。大家都知道场景很大,但是具体的挑战在哪里?谁能target这些问题而不是盲目入局,才是判断这个赛道优秀项目的核心。
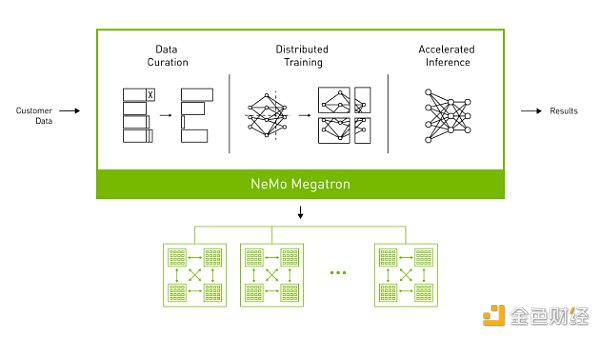
以训练一个具有1750亿参数的大模型为例。由于模型规模巨大,需要在很多个GPU设备上进行并行训练。假设有一个中心化的机房,有100个GPU,每个设备具有32GB的内存。
这个过程涉及到大量的数据传输和同步,这可能会成为训练效率的瓶颈。因此,优化网络带宽和延迟,以及使用高效的并行和同步策略,对于大规模模型训练非常重要。
需要注意的是,通信的瓶颈也是导致现在分布式算力网络做不了大语言模型训练的原因。
各个节点需要频繁地交换信息以协同工作,这就产生了通信开销。对于大语言模型,由于模型的参数数量巨大这个问题尤为严重。通信开销分这几个方面:
虽然有一些方法可以减少通信开销,比如参数和梯度的压缩、高效并行策略等,但是这些方法可能会引入额外的计算负担,或者对模型的训练效果产生负面影响。并且,这些方法也不能完全解决通信开销问题,特别是在网络条件差或计算节点之间的距离较大的情况下。
举一个例子:
GPT-3模型有1750亿个参数,如果我们使用单精度浮点数(每个参数4字节)来表示这些参数,那存储这些参数就需要~700GB的内存。而在分布式训练中,这些参数需要在各个计算节点之间频繁地传输和更新。
假设有100个计算节点,每个节点每个步骤都需要更新所有的参数,那么每个步骤都需要传输约70TB(700GB*100)的数据。如果我们假设一个步骤需要1s(非常乐观的假设),那么每秒钟就需要传输70TB的数据。这种对带宽的需求已经远超过了大多数网络,也是一个可行性的问题。
- 星际资讯
免责声明:投资有风险,入市须谨慎。本资讯不作为投资建议。