人类数据,要被OpenAI用完了,然后呢?
文章转载来源:极客公园
 图片来源:由无界 AI 生成
图片来源:由无界 AI 生成‘比大更大’(Bigger than bigger)当年苹果的一句广告词,用来形容现在 AI 领域最热的大语言模型,看起来也没什么不对。
从十亿、百亿再到千亿,大模型的参数走向逐渐狂野,相应的,用来训练 AI 的数据量,也以指数级暴增。
以 OpenAI 的 GPT 为例,从 GPT-1 到 GPT-3,其训练数据集就从 4.5GB 指数级增长到了 570GB。
不久前的 Databricks 举办的 Data+AI 大会上,a16z 创始人 Marc Andreessen 认为,二十几年来互联网积累的海量数据,是这一次新的 AI 浪潮兴起的重要原因,因为前者为后者提供了可用来训练的数据。
但是,即便网民们在网上留下了大量有用或者没用的数据,对于 AI 训练来说,这些数据,可能要见底了。
人工智能研究和预测组织 Epoch 发表的一篇论文里预测,高质量的文本数据会在 2023-2027 年之间消耗殆尽。
尽管研究团队也承认,分析方法存在严重的局限,模型的不准确性很高,但是很难否认,AI 消耗数据集的速度是恐怖的。
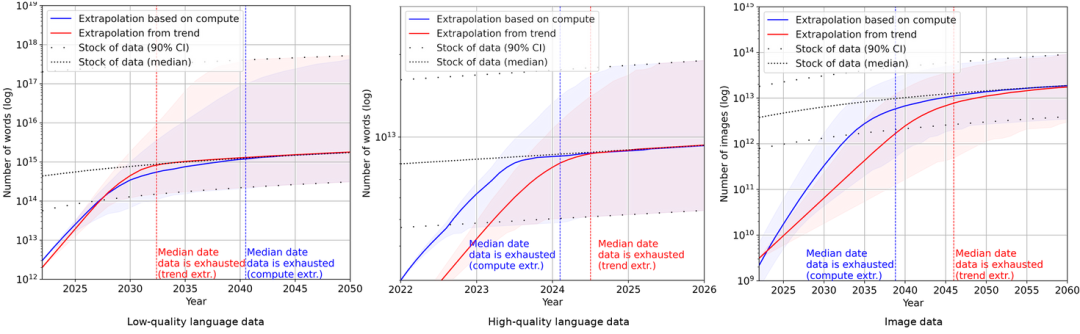
低质量文本、高质量文本和图像的机器学习数据消耗和数据生产趋势|EpochAI
当‘人类’数据用完,AI 训练不可避免地,将会使用 AI 自己生产的内容。不过,这样的‘内循环’,却会产生很大挑战。
不久前,来自剑桥大学、牛津大学、多伦多大学等高校的研究人员发表论文指出,用 AI 生成的内容作为训练 AI,会导致新模型的崩溃。
所以,AI 训练用‘生成数据’会带来崩溃的原因是什么?还有救吗?
01 AI‘近亲繁殖’的后果
在这篇名为《递归的诅咒:用生成数据训练会使模型遗忘》的论文中,研究人员指出,
http://news.utalk.vip/flash//2023/0718/36565.html - 星际资讯
免责声明:投资有风险,入市须谨慎。本资讯不作为投资建议。