OpenAI:ChatGPT将遵守爬虫协议,网站可拒绝白嫖
文章转载来源:AIcore
原文来源:量子位
不希望网站数据被ChatGPT白嫖?现在终于有办法了!
两行代码就能搞定,而且是OpenAI官方公布的那种。

刚刚,OpenAI在用户文档中更新了GPTBot的说明。
根据这一说明,内容拥有者将可以拒绝网站数据被ChatGPT的爬虫抓取。
这是继暂停网页访问功能之后,OpenAI在版权和隐私保护方面的又一重大举措。

不过,OpenAI还是希望能内容拥有者将访问权限开放给GPTBot。
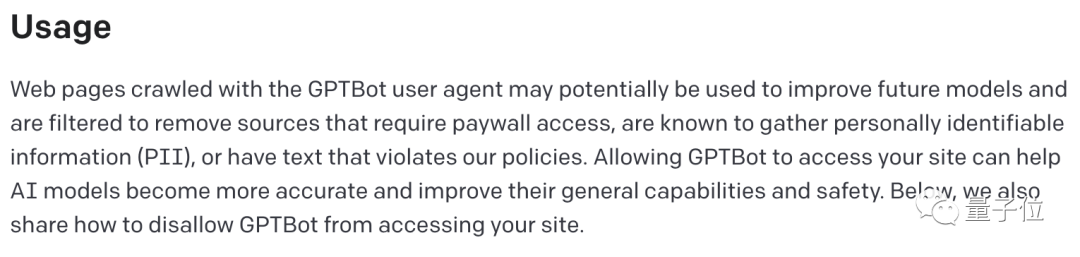
在这份关于GPTBot的说明中,OpenAI表示:
允许我们的爬虫访问你的数据有利于使AI模型更精确、更安全。
但至少,站主们拥有了选择的权利。
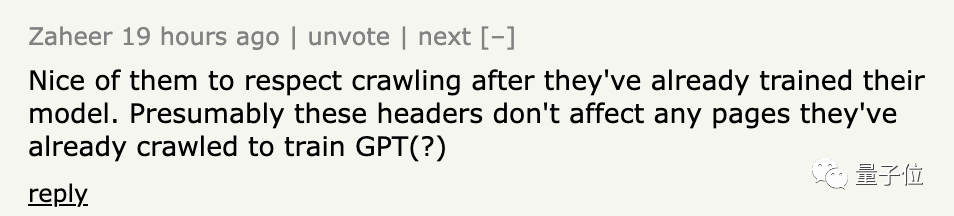
不过,也有网友指出了问题:
模型早就已经训练好了,现在提这个还有什么用?
对此OpenAI尚未作出解释,我们还是先来看看这次的措施。
三种方式阻止GPT爬虫
那么,OpenAI都公布了哪些内容呢?
首先是GPTBot的U(ser)A(gent)信息。
User agent token: GPTBot
Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
UA是浏览器的身份标识,包含了访问者的系统环境、浏览器内核版本、语言等诸多信息。通过HTML的标签,可以阻止特定的浏览器对网页内容进行访问。在这份说明文档中,OpenAI还提供了更简单的爬虫阻止方式,即修改robots.txt。只要在网站的robots.txt中加入如下内容:
- 星际资讯
免责声明:投资有风险,入市须谨慎。本资讯不作为投资建议。