逐鹿金融大模型,商业化将向何处?
文章转载来源:AI之势
原文来源:零壹财经
作者:沈拙言
 图片来源:由无界 AI 生成
图片来源:由无界 AI 生成在关于金融大模型的诸多讨论中,“落地应用”成了最终关键词。
对金融业务而言,精准与安全合规是任何技术得以应用的最大前提。因此,金融大模型的应用便绝非简单的“拿来主义”,需要在通用基础上结合业务需求反复精调,这也是当前金融大模型的主要发力点。
7月末,据腾讯研究院副秘书长杨望调研分析,国内参数在10亿规模以上的大模型数量已由5月末的79个增加至116个,其中金融行业大模型约18个。
有观点认为,大模型的出现,可能会把金融机构的数字化转型进程拉到同一起跑线,填补金融机构间的“转型鸿沟”,这对中小金融机构来讲是不容错过的机遇。
在保证信息精度与安全合规的前提下,抢先获得金融业务场景的商用突破,成为18家金融大模型研发机构竞争的决胜点。
各显神通抢赛道
3月底,全球最大的财经资讯公司彭博社发布拥有500亿参数的大型语言模型——BloombergGPT,标志着全球首个金融大模型的诞生,也掀起了国内金融大模型的浪潮。
彭博社表示,该大模型在3630tokens金融数据集、3450亿tokens公共数据集之上进行训练,可全方位支持金融领域NLP(自然语言处理)任务,表现明显优于其他类似规模的开放模型,在一般NLP基准上的表现也达到甚至超过平均水平。
BloombergGPT一声炮响,给国内带来了实践方向。
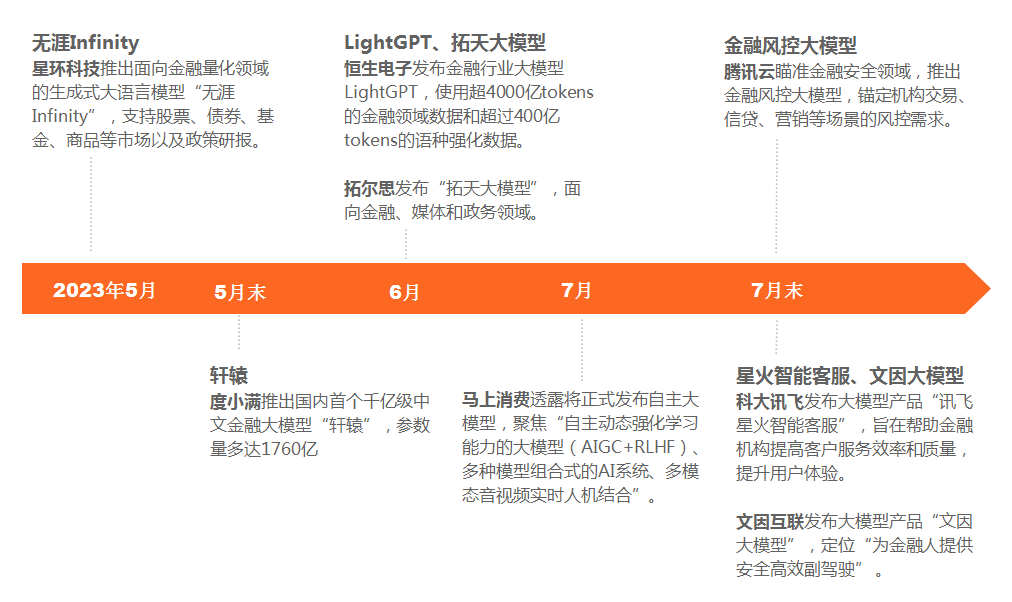 图1:国内主要金融大模型时间轴(不完全统计)
图1:国内主要金融大模型时间轴(不完全统计)来源:零壹智库
5月,大数据基础软件供应商星环科技推出第一款面向金融量化领域的生成式大语言模型“无涯Infinity”。
- 星际资讯
免责声明:投资有风险,入市须谨慎。本资讯不作为投资建议。