Foresight Ventures: 理性看待去中心化算力网络
•
2023-06-01 00:00:00
•
Meta •
阅读
TL;DR
- 目前AI + Crypto结合的点主要有2个比较大的方向:分布式算力和ZKML;关于ZKML可以参考我之前的一篇文章。本文将围绕去中心化的分布式算力网络做出分析和反思。
- 在AI大模型的发展趋势下,算力资源会是下一个十年的大战场,也是未来人类社会最重要的东西,并且不只是停留在商业竞争,也会成为大国博弈的战略资源。未来对于高性能计算基础设施、算力储备的投资将会指数级上升。
- 去中心化的分布式算力网络在AI大模型训练上的需求是最大的,但是也面临最大的挑战和技术瓶颈。包括需要复杂的数据同步和网络优化问题等。此外,数据隐私和安全也是重要的制约因素。虽然有一些现有的技术能提供初步解决方案,但在大规模分布式训练任务中,由于计算和通信开销巨大,这些技术仍无法应用。
- 去中心化的分布式算力网络在模型推理上更有机会落地,可以预测未来的增量空间也足够大。但也面临通信延迟、数据隐私、模型安全等挑战。和模型训练相比,推理时的计算复杂度和数据交互性较低,更适合在分布式环境中进行。
- 通过Together和Gensyn.ai两个初创公司的案例,分别从技术优化和激励层设计的角度说明了去中心化的分布式算力网络整体的研究方向和具体思路。
一、分布式算力—大模型训练
我们在讨论分布式算力在训练时的应用,一般聚焦在大语言模型的训练,主要原因是小模型的训练对算力的需求并不大,为了做分布式去搞数据隐私和一堆工程问题不划算,不如直接中心化解决。而大语言模型对算力的需求巨大,并且现在在爆发的最初阶段,2012-2018,AI的计算需求大约每4个月就翻一倍,现在更是对算力需求的集中点,可以预判未来5-8年仍然会是巨大的增量需求。
在巨大机遇的同时,也需要清晰的看到问题。大家都知道场景很大,但是具体的挑战在哪里?谁能target这些问题而不是盲目入局,才是判断这个赛道优秀项目的核心。
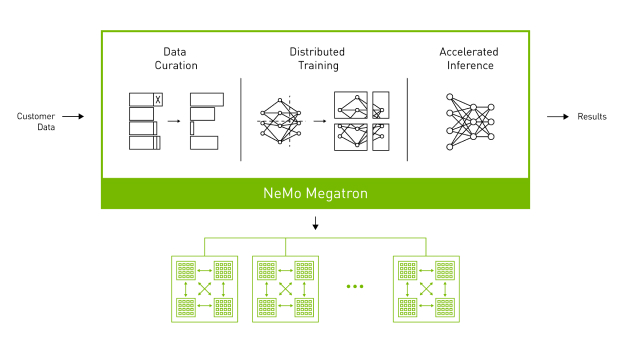 (NVIDIA NeMo Megatron Framework)
(NVIDIA NeMo Megatron Framework)
1.整体训练流程
以训练一个具有1750亿参数的大模型为例。由于模型规模巨大,需要在很多个GPU设备上进行并行训练。假设有一个中心化的机房,有100个GPU,每个设备具有32GB的内存。
- 星际资讯
免责声明:投资有风险,入市须谨慎。本资讯不作为投资建议。
下一篇:没有了
« 上一篇
上一篇:研报:2023上半年NFT交易赛道发展分析
下一篇 »