OpenAI“政变”进行时,“百模大战”接下来该战什么?
文章转载来源:Model进化论
原文来源:脑极体
 图片来源:由无界 AI生成
图片来源:由无界 AI生成这两天AI圈最热闹的消息,应该就OpenAI高层内讧,标志性人物、原CEO Sam Altman被董事会解雇,数位科学家和高层离职。
关于“政变”的原因,坊间有很多传言,比如商业化和非营利原则的矛盾。总之,事件相关者在舆论场拉扯,吃瓜群众则瞪大了眼睛看戏。这场风波会给全球AI研发,尤其是大模型带来什么影响,还是未知数。
有人做了一个梗图,大模型厂商乱成一锅粥,只有卖卡的英伟达稳坐钓鱼台。
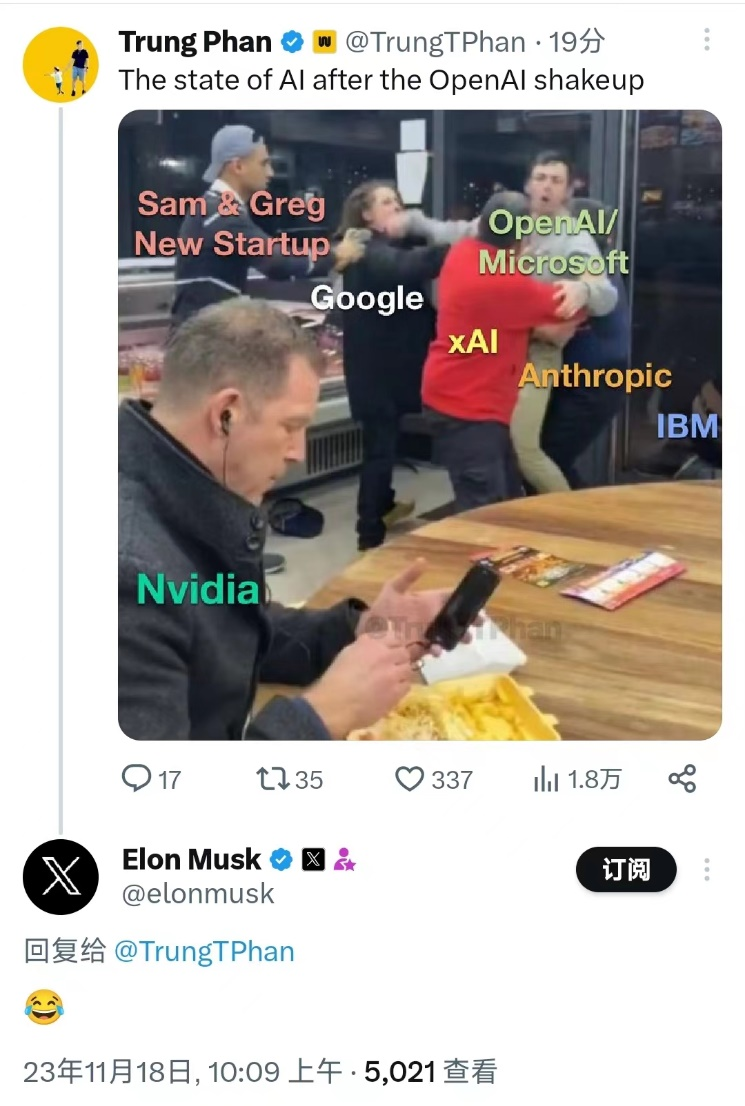
任它天边云卷云舒,可以肯定的是,中国的AI大模型在取得广泛成就的基础上,会继续向前发展,释放产业价值,并且不会一味照搬海外,尤其是OpenAI的模式。
带着这份淡定,我们将目光聚焦在国产大模型,会发现“百模大战”热潮中,还缺乏对各类大模型全面、分层、真实的能力评估。
通用大模型、行业大模型,都在比拼参数规模,但训练数据质量不确定,仅凭参数,行业客户和用户也难以选对适合的大模型。
那么看榜单呢?基准测试benchmark和标准化数据集,可以针对性调优,榜单无法反映实际应用效果差距。
而且大模型在不同任务场景下,表现的区分度很大。一位开发者说,“现在就是告诉你都有哪些大模型,实际效果还是得靠自己测测看”。
据中国信通院的数据显示,目前的大模型测试方法和数据集已有200多个。想要一个个测过来,会给用户带来非常繁重的工作量。
“百模大战”乱花渐欲迷人眼,那么,除了“跑分”打榜和参数“碾压”,还有什么办法来真实且有效地评判一个大模型的水平呢?
有必要来聊聊,“百模大战”,不同赛道都在战什么?
大模型,不看高分看高能
- 星际资讯
免责声明:投资有风险,入市须谨慎。本资讯不作为投资建议。